准确率创新高,北大开源中文分词工具包 pkuseg
本文共 565 字,大约阅读时间需要 1 分钟。
北京大学近日开源了一个全新的中文分词工具包 pkuseg ,相比于现有的同类开源工具,pkuseg 大幅提高了分词的准确率。
pkuseg 由北大语言计算与机器学习研究组研制推出,具备如下特性:
-
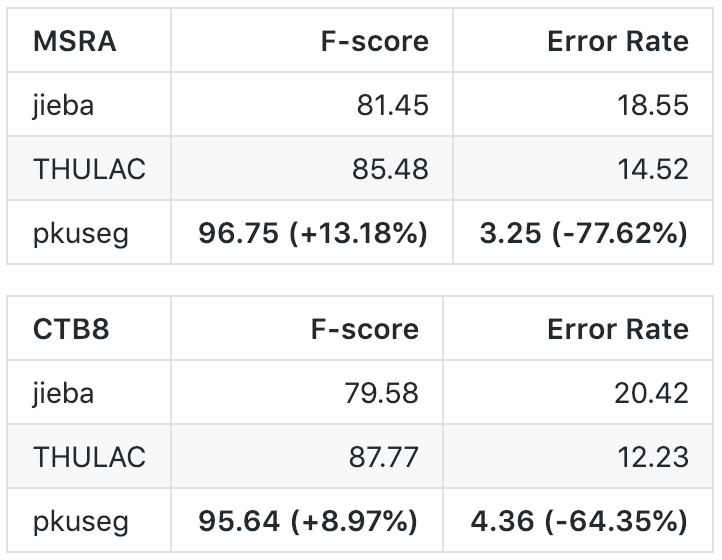
高分词准确率。相比于其他的分词工具包,pkuseg 在不同领域的数据上都大幅提高了分词的准确度。根据项目文档给出的测试结果,pkuseg 分别在示例数据集( MSRA 和 CTB8 )上降低了 79.33% 和 63.67% 的分词错误率。
-
多领域分词。研究组训练了多种不同领域的分词模型。根据待分词的领域特点,用户可以自由地选择不同的模型。
-
支持用户自训练模型。支持用户使用全新的标注数据进行训练。
性能对比
在 Linux 环境下,各工具在新闻数据 (MSRA) 和混合型文本 (CTB8) 数据上的准确率测试情况如下:
预训练模型
分词模式下,用户需要加载预训练好的模型。我们提供了三种在不同类型数据上训练得到的模型,根据具体需要,用户可以选择不同的预训练模型。以下是对预训练模型的说明:
MSRA : 在 MSRA(新闻语料)上训练的模型。新版本代码采用的是此模型。
CTB8 : 在 CTB8(新闻文本及网络文本的混合型语料)上训练的模型。
WEIBO : 在微博(网络文本语料)上训练的模型。
更多详情可查阅。
原文地址:
转载地址:http://iuzhj.baihongyu.com/
你可能感兴趣的文章
数据结构之列表
查看>>
发布/订阅模式 vs 观察者模式
查看>>
es5中的arguments对象
查看>>
git本地仓库和远程仓库关联,分支重命名
查看>>
js对象的深拷贝,你真的觉得很简单吗?
查看>>
你真的了解map方法吗?手动实现数组map方法。
查看>>
带你手动实现call方法,让你收获满满
查看>>
前端知识体系
查看>>
查找入职员工时间排名倒数第三的员工所有信息
查看>>
使用join查询方式找出没有分类的电影id以及名称
查看>>
Qt教程(2) : Qt元对象系统
查看>>
驱动开发误用指针错误:Unable to handle kernel NULL pointer dereference at virtual address
查看>>
Linux部署DocSystem知识/文件管理系统
查看>>
Centos7开机自启动脚本无法使用备用方案
查看>>
jvm虚拟机内存详解
查看>>
线程的创建方式
查看>>
DNS是什么
查看>>
mapreduce自定义分组、自定义分区、二次排序
查看>>
Hbase架构
查看>>
spark运行模式
查看>>